Attention
Shield: ![]()
These images were originally published in the book “Deep Learning with PyTorch Step-by-Step: A Beginner’s Guide”.
They are also available at the book’s official repository: https://github.com/dvgodoy/PyTorchStepByStep.
Index
** CLICK ON THE IMAGES FOR FULL SIZE **
Papers
- Encoder-Decoder Architecture: Sequence to Sequence Learning with Neural Networks by Sutskever, I. et al. (2014)
- Scaled Dot Product / Self-Attention: Attention Is All You Need by Vaswani, A. et al. (2017)
Attention
Scaled Dot Product
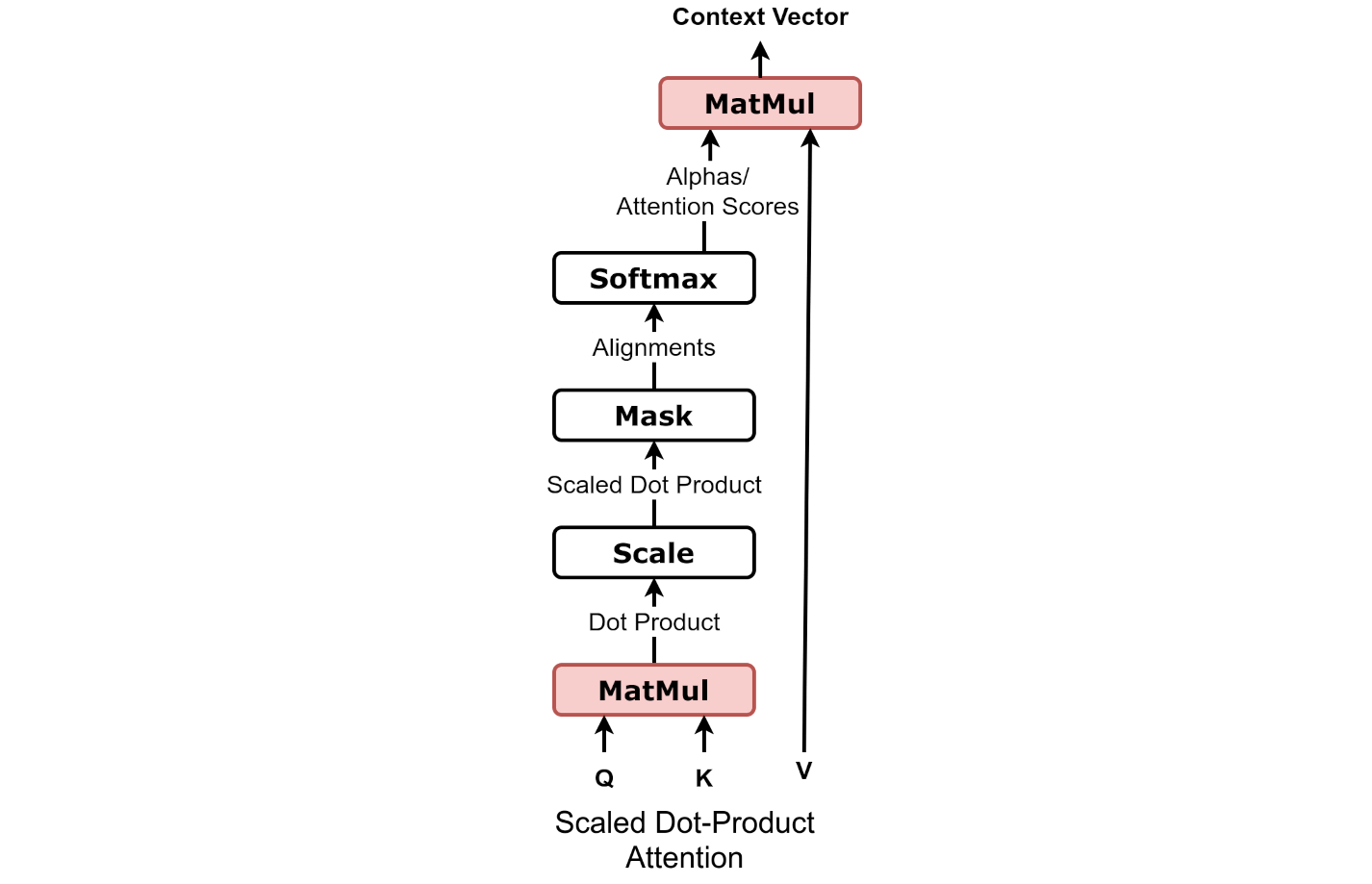 Source: Chapter 9
Source: Chapter 9
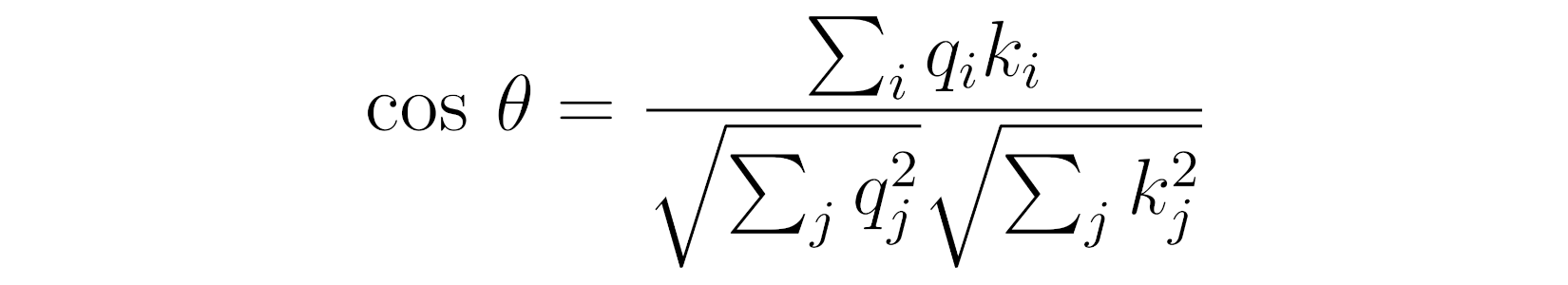 Source: Chapter 9
Source: Chapter 9
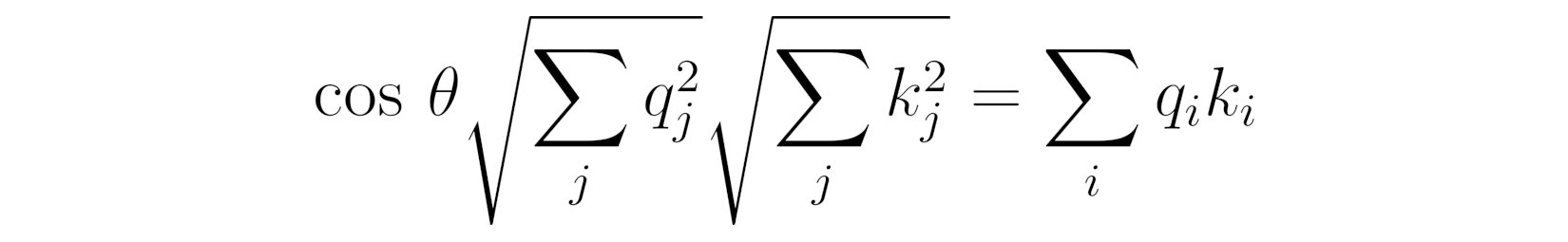 Source: Chapter 9
Source: Chapter 9
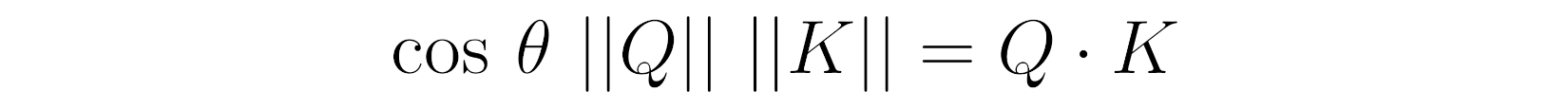 Source: Chapter 9
Source: Chapter 9
 Source: Chapter 9
Source: Chapter 9
Alignment Scores
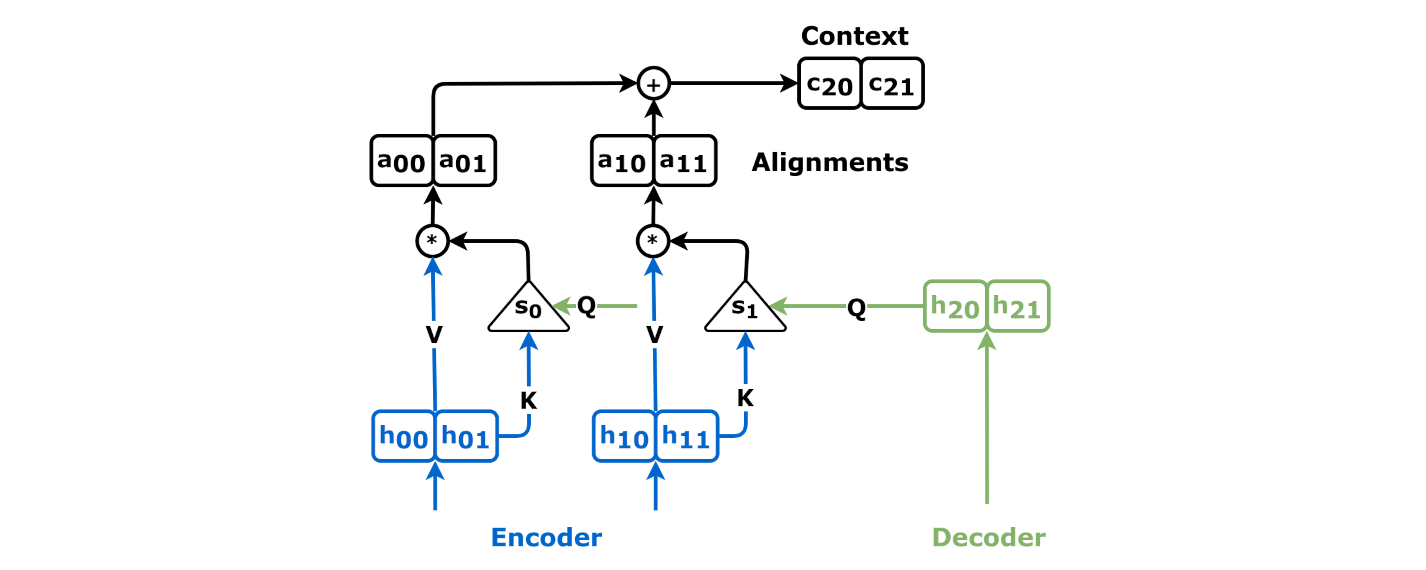 Source: Chapter 9
Source: Chapter 9
Context Vector
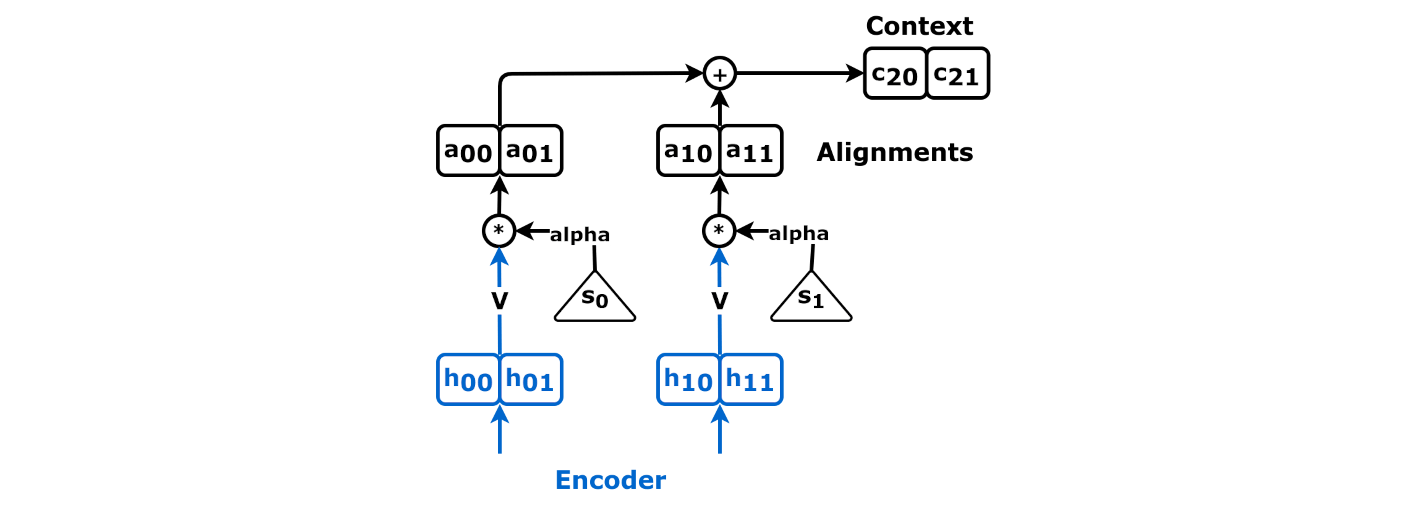 Source: Chapter 9
Source: Chapter 9
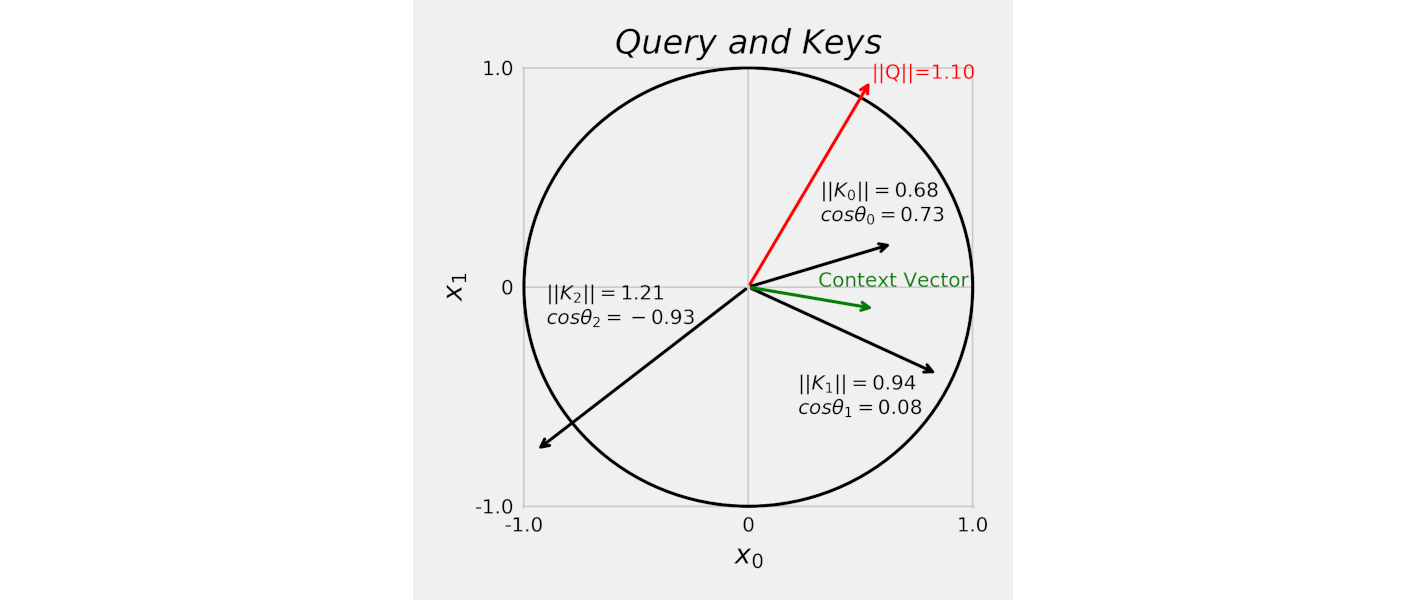 Source: Chapter 9
Source: Chapter 9
Attention Scores
Encoder
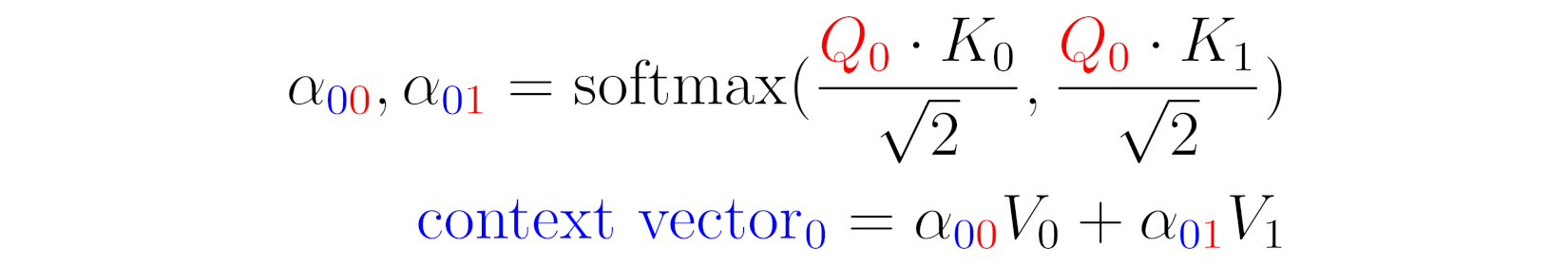 Source: Chapter 9
Source: Chapter 9
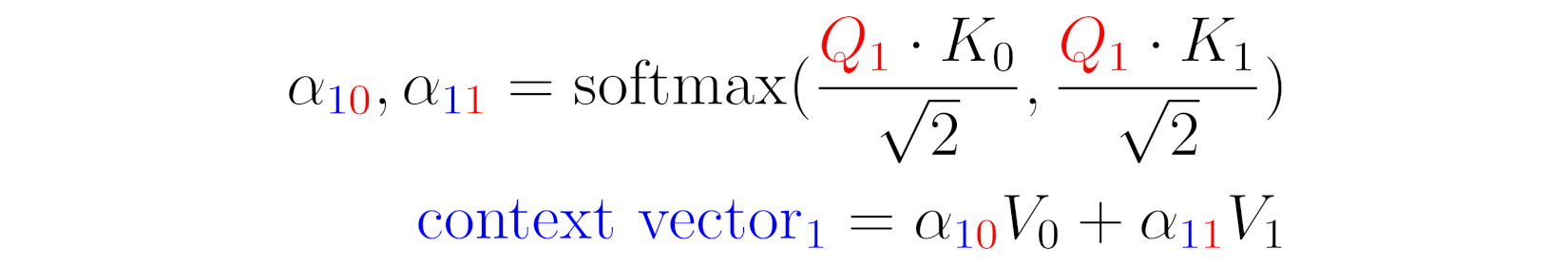 Source: Chapter 9
Source: Chapter 9
Decoder
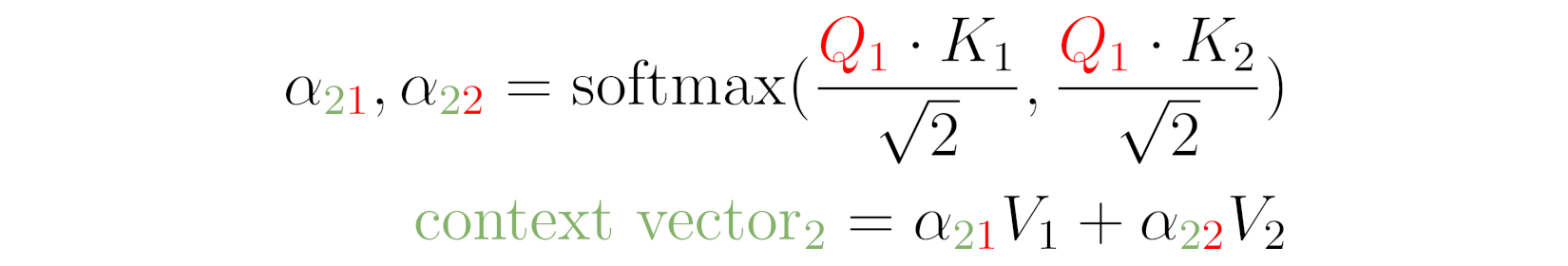 Source: Chapter 9
Source: Chapter 9
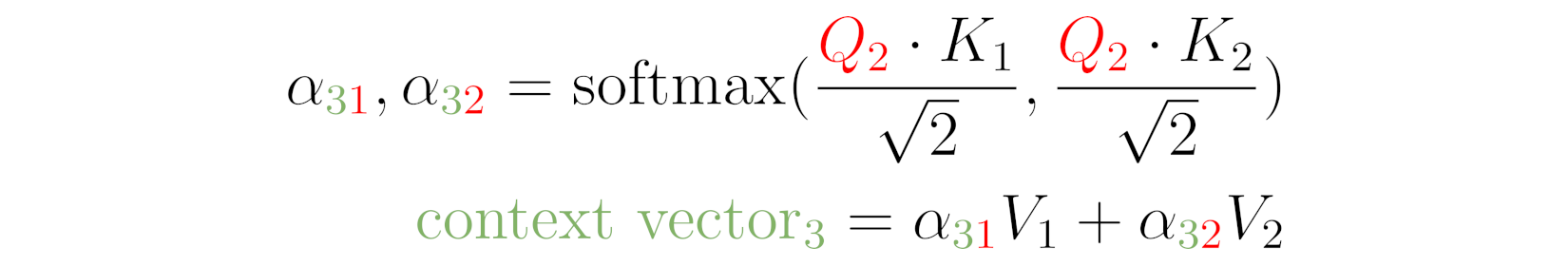 Source: Chapter 9
Source: Chapter 9
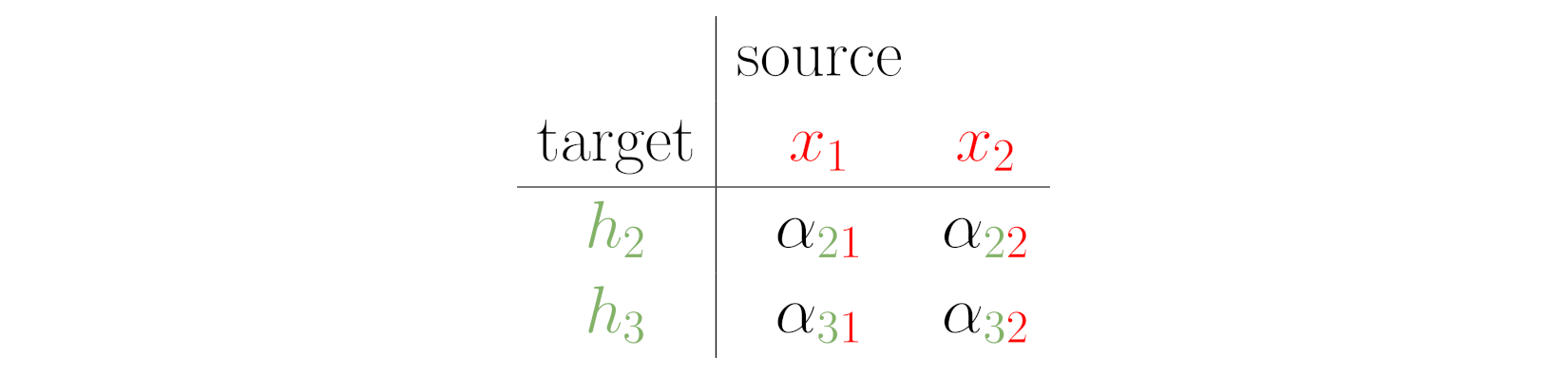 Source: Chapter 9
Source: Chapter 9
Masked
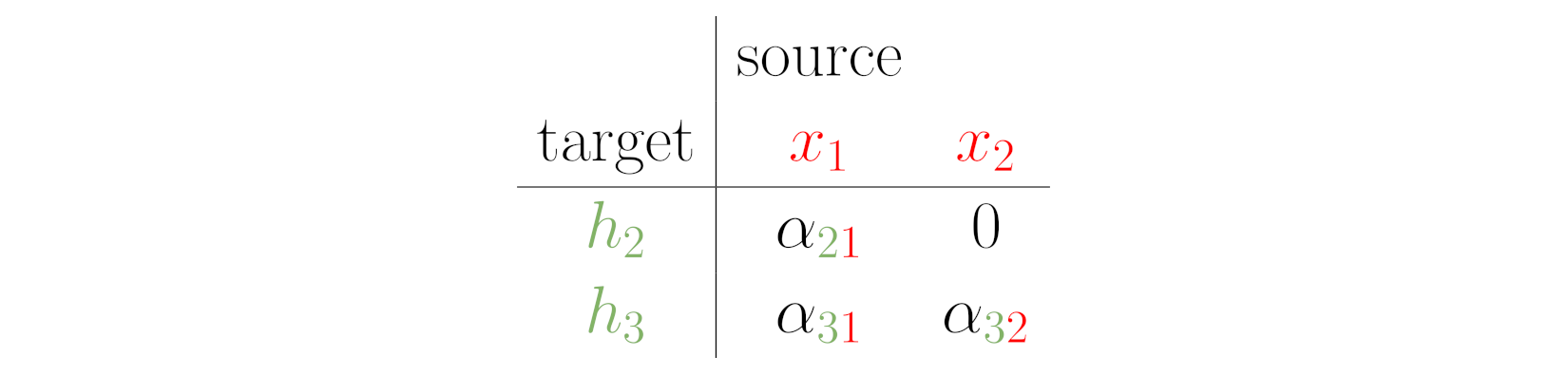 Source: Chapter 9
Source: Chapter 9
Cross-Attention
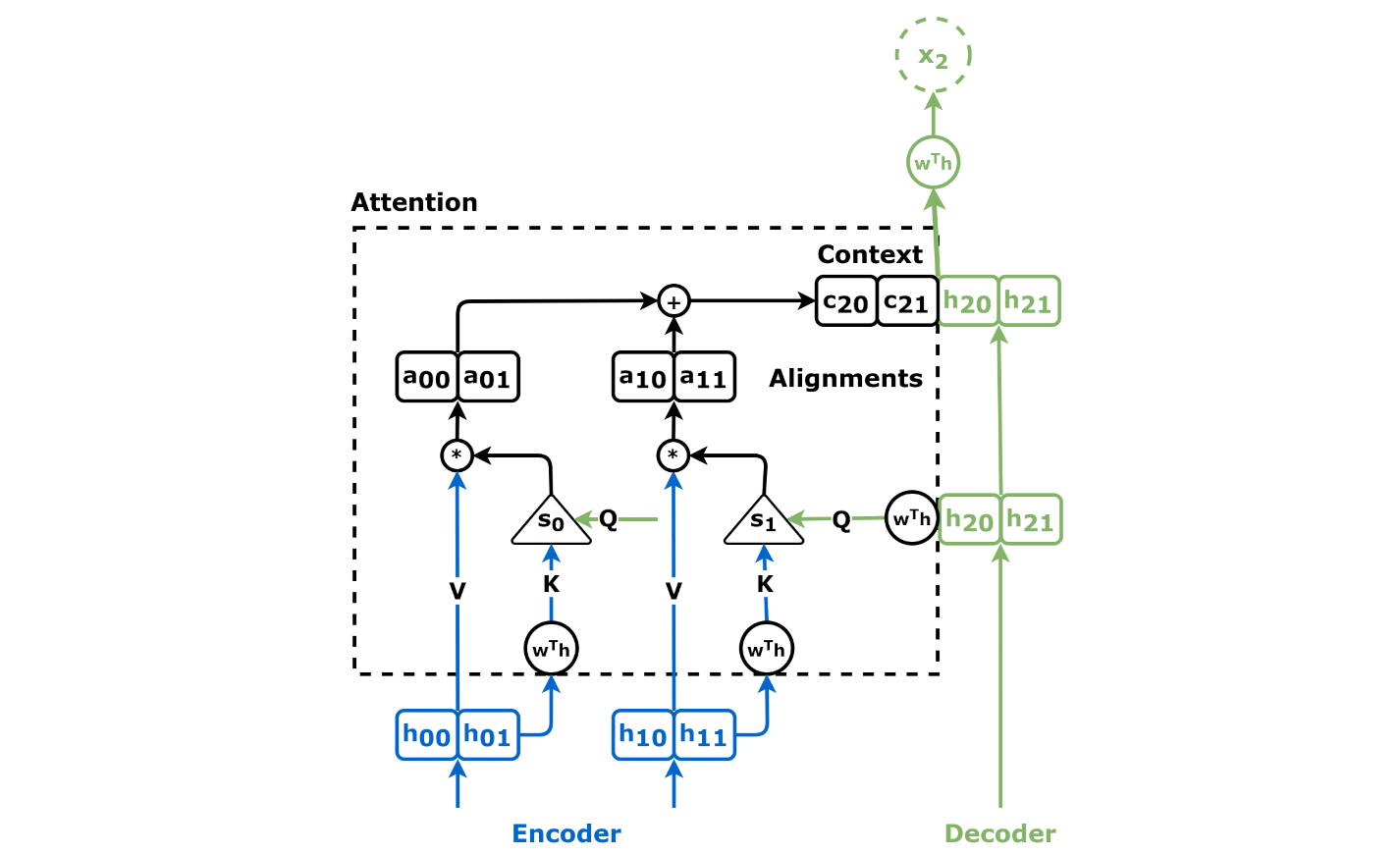 Source: Chapter 9
Source: Chapter 9
 Source: Chapter 9
Source: Chapter 9
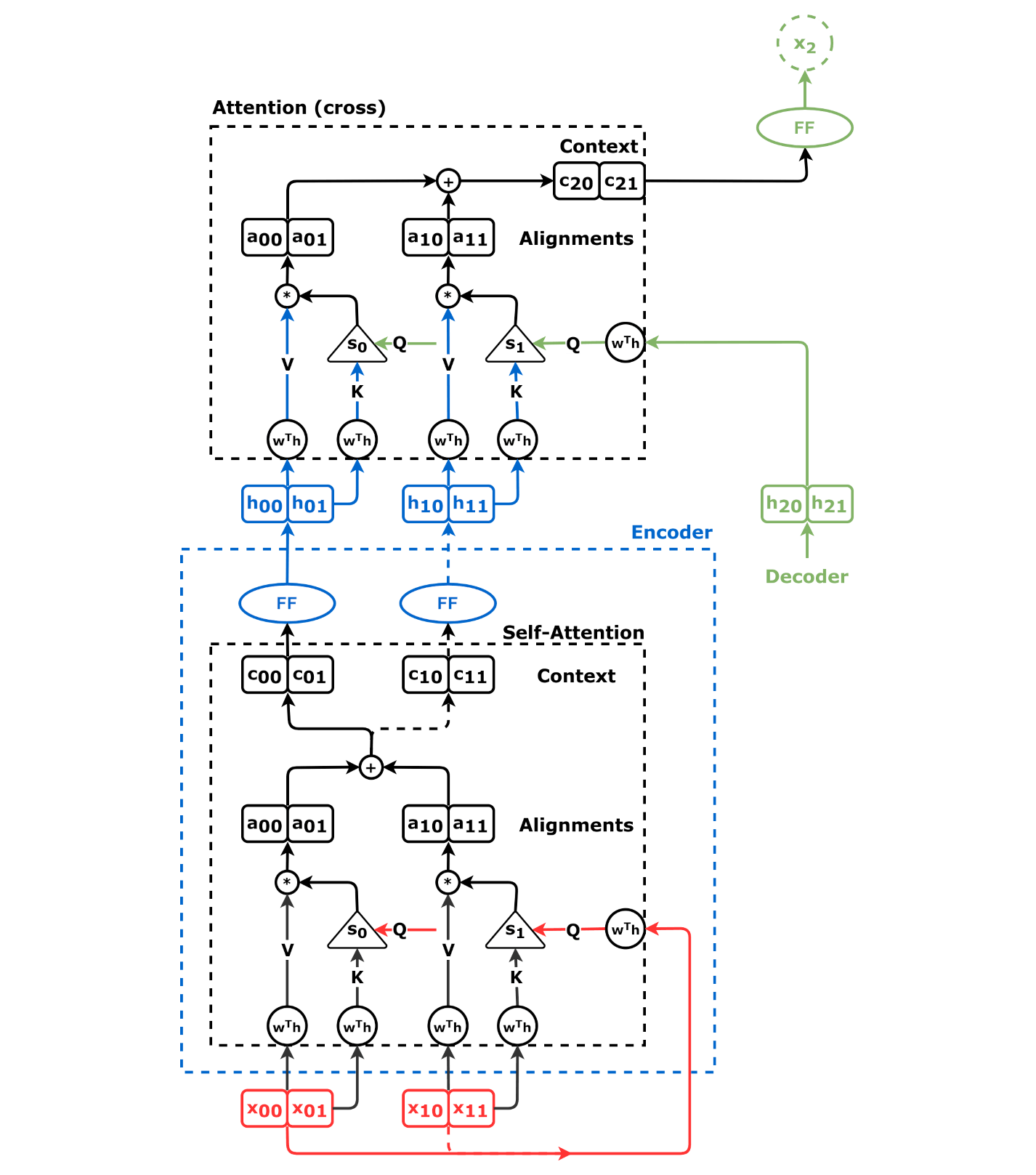
Encoder+Decoder+Cross-Attention
 Source: Chapter 9
Source: Chapter 9
Translation Example
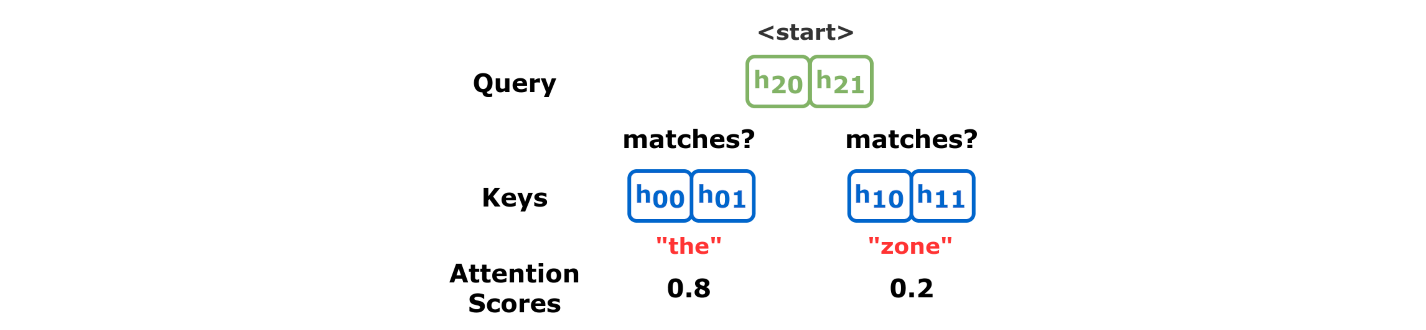 Source: Chapter 9
Source: Chapter 9
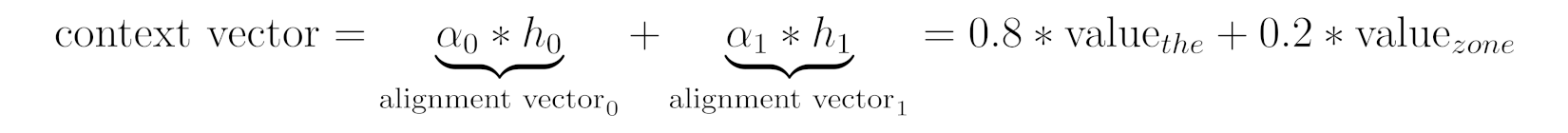 Source: Chapter 9
Source: Chapter 9
![]() Source: Chapter 9
Source: Chapter 9
![]() Source: Chapter 9
Source: Chapter 9
![]() Source: Chapter 9
Source: Chapter 9
![]() Source: Chapter 9
Source: Chapter 9
Multi-Headed Attention
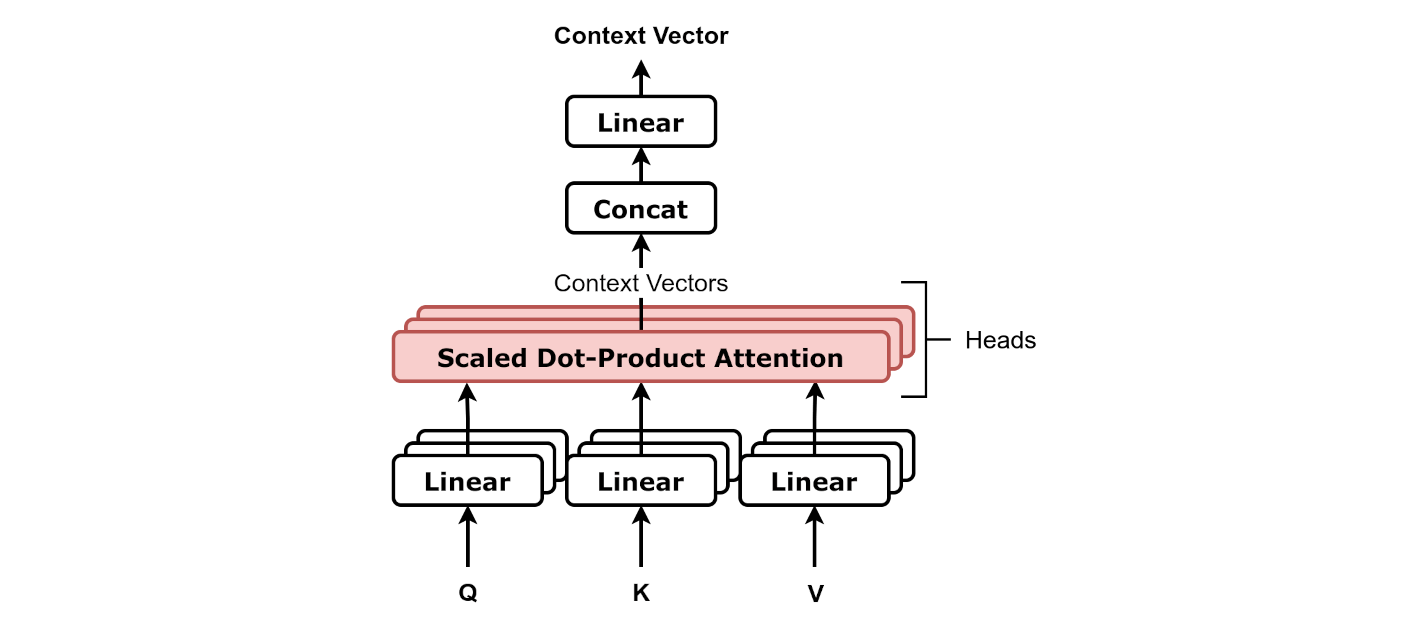 Source: Chapter 9
Source: Chapter 9
Wide Attention
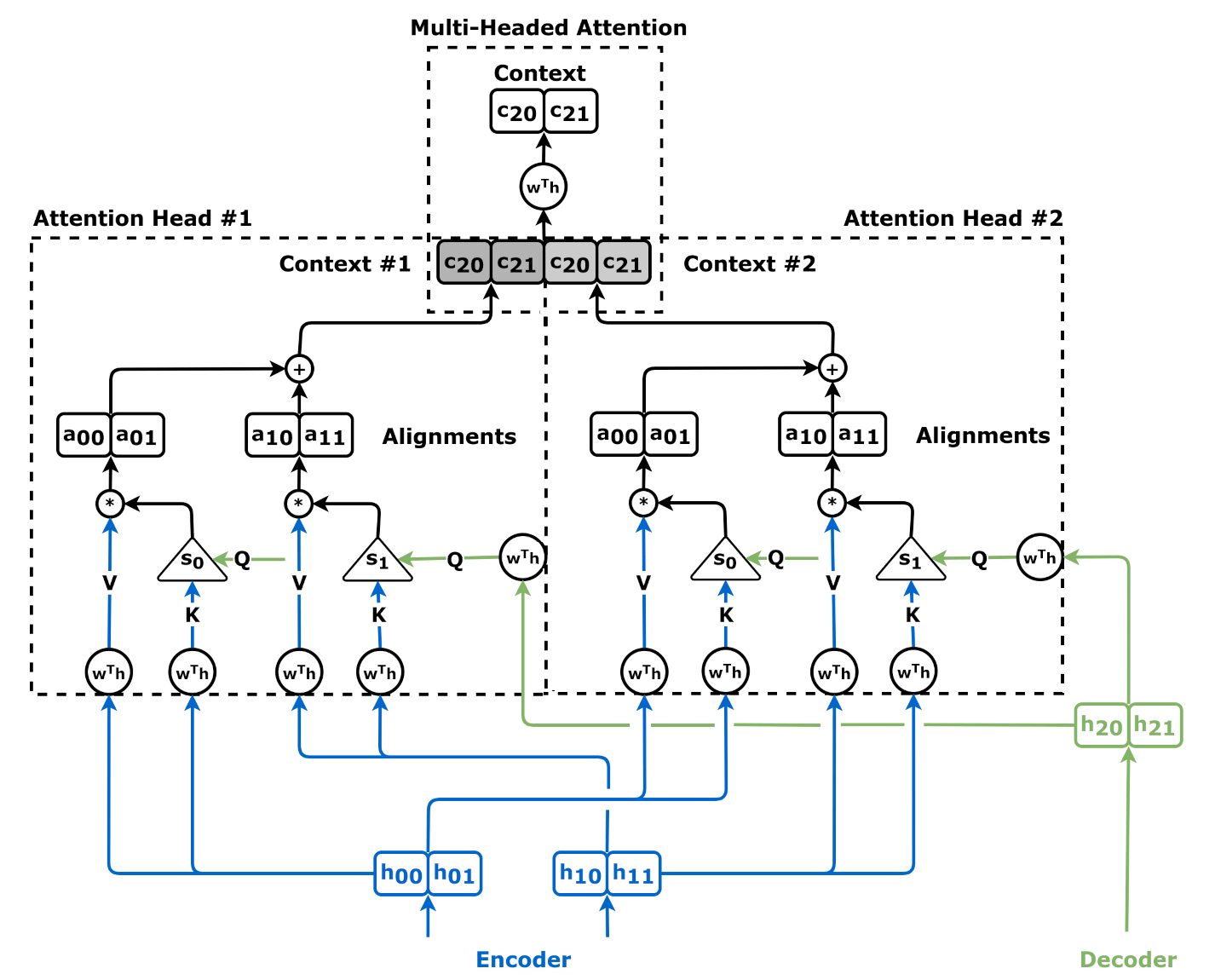 Source: Chapter 9
Source: Chapter 9
Narrow Attention
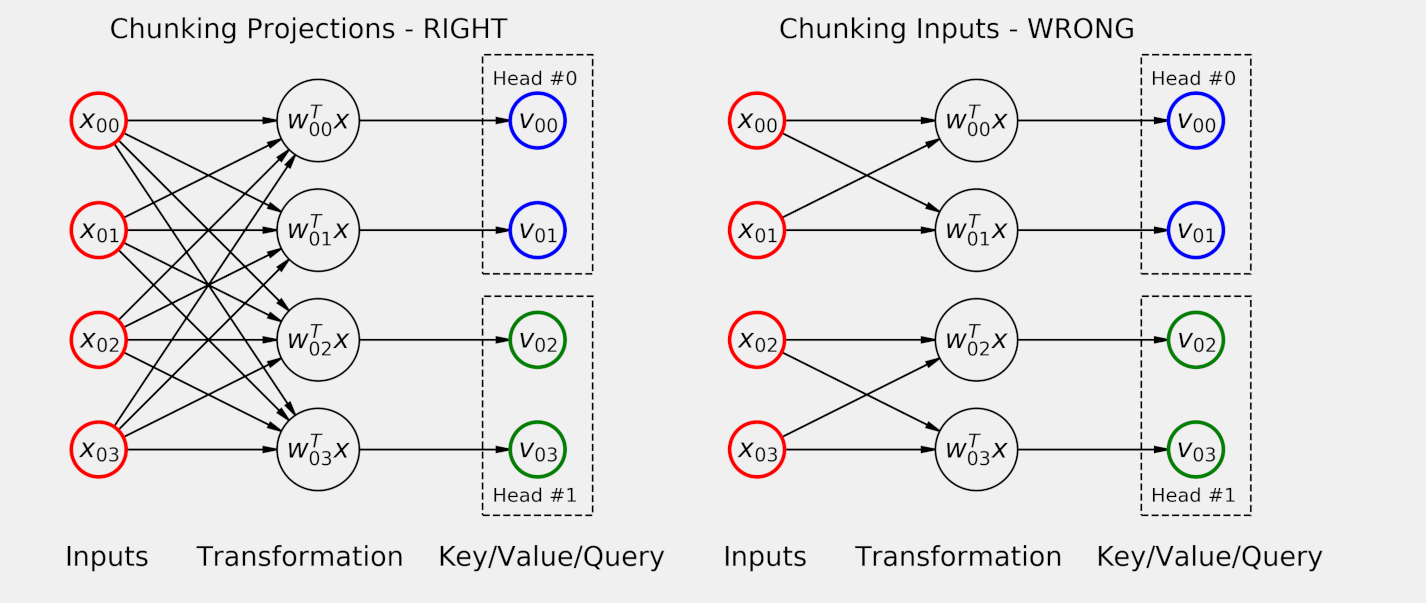 Source: Chapter 10
Source: Chapter 10
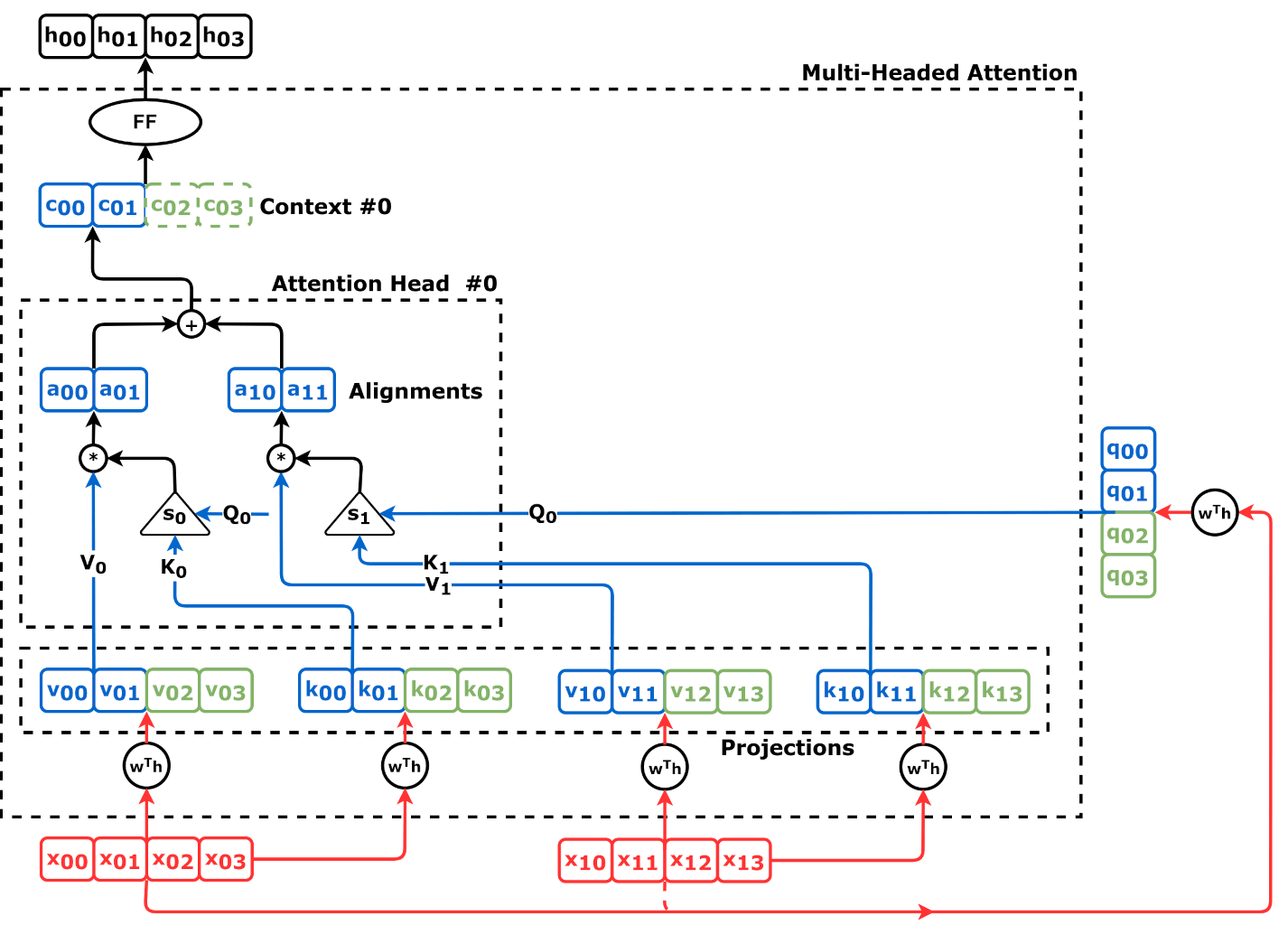 Source: Chapter 10
Source: Chapter 10
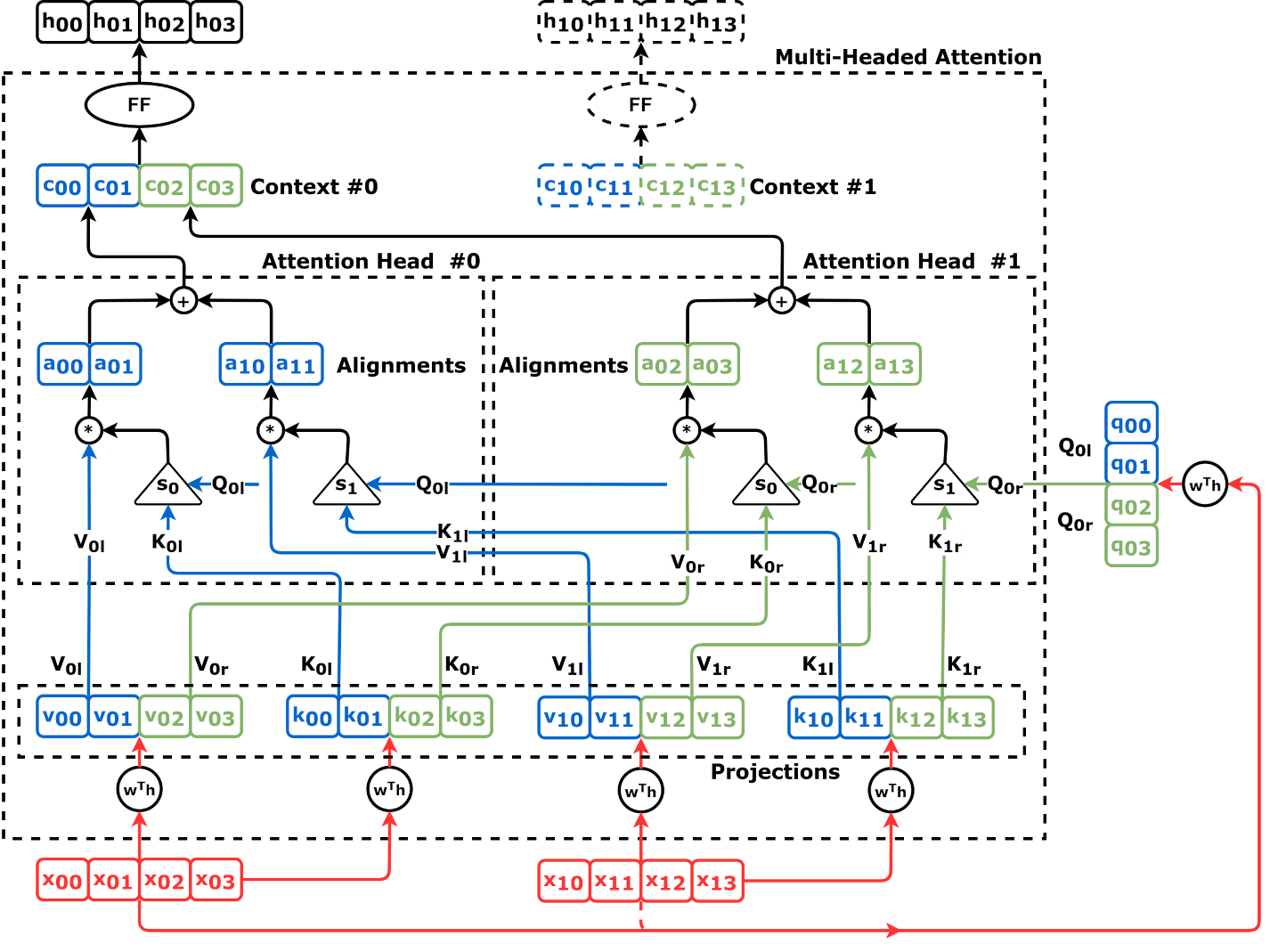 Source: Chapter 10
Source: Chapter 10
Self-Attention
Self-Attention Encoder
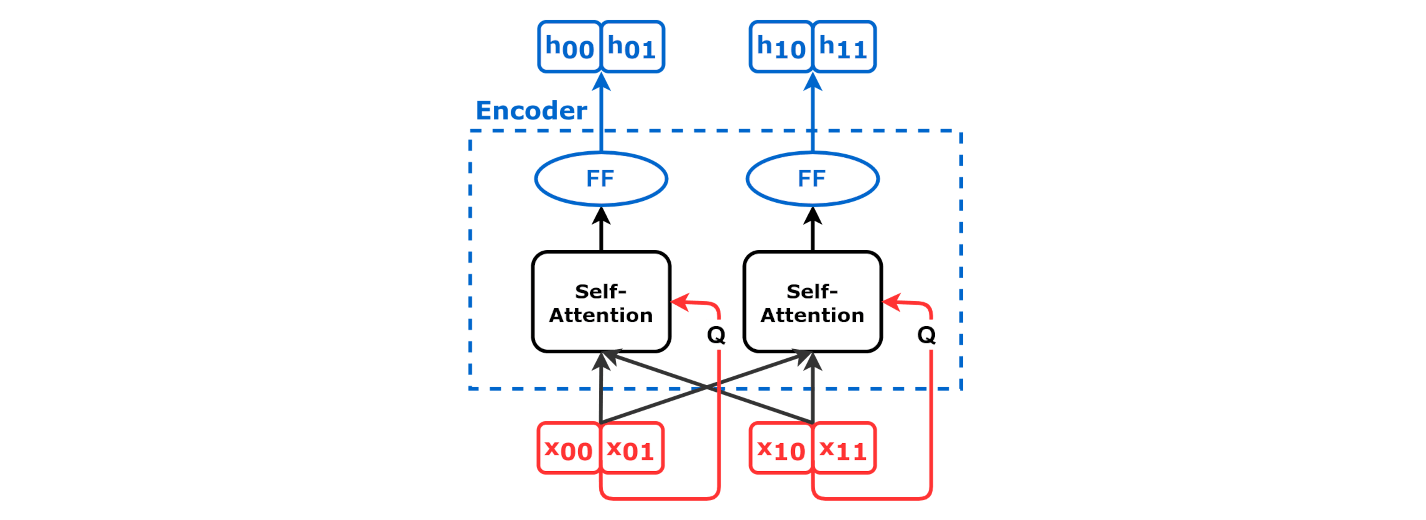 Source: Chapter 9
Source: Chapter 9
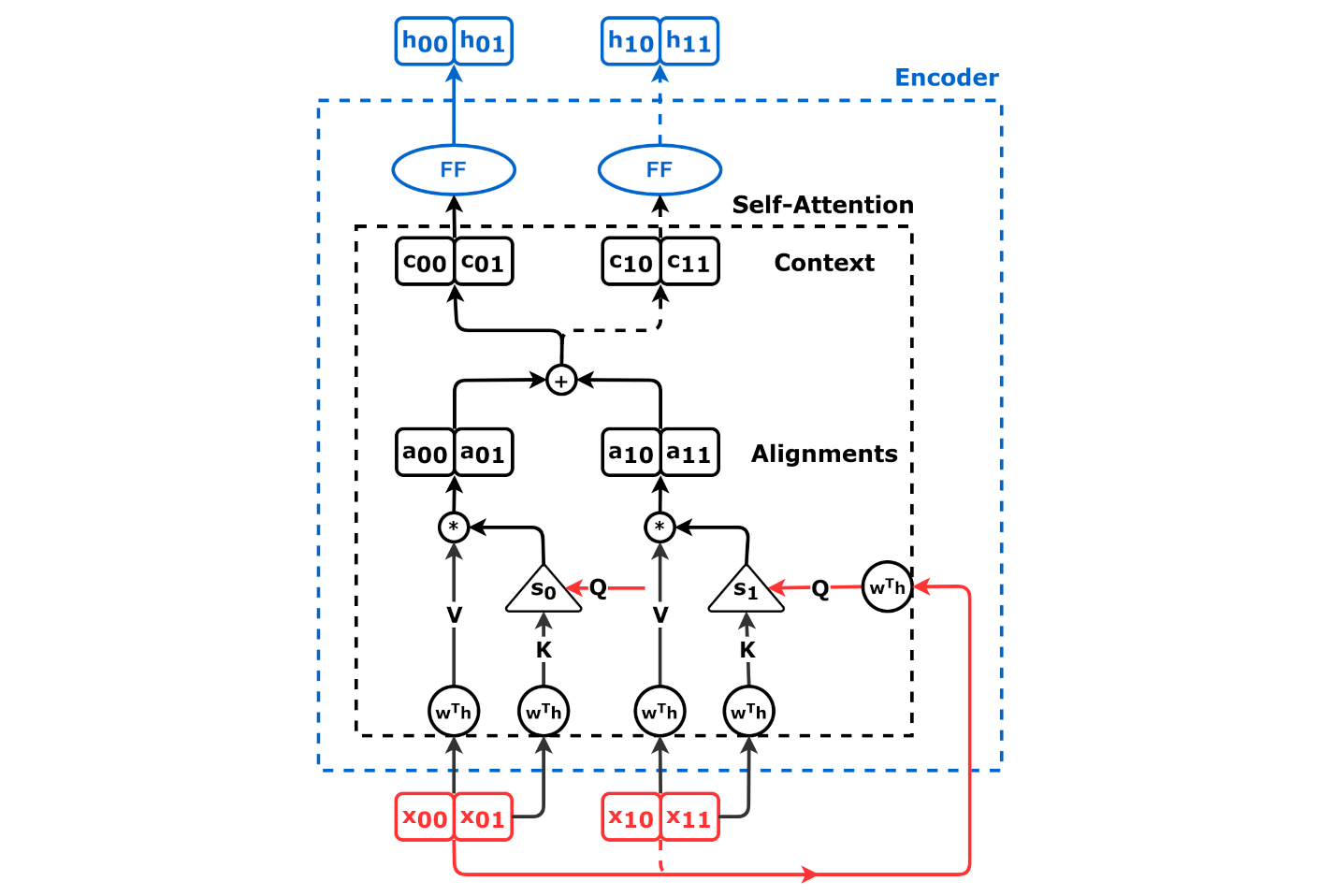 Source: Chapter 9
Source: Chapter 9
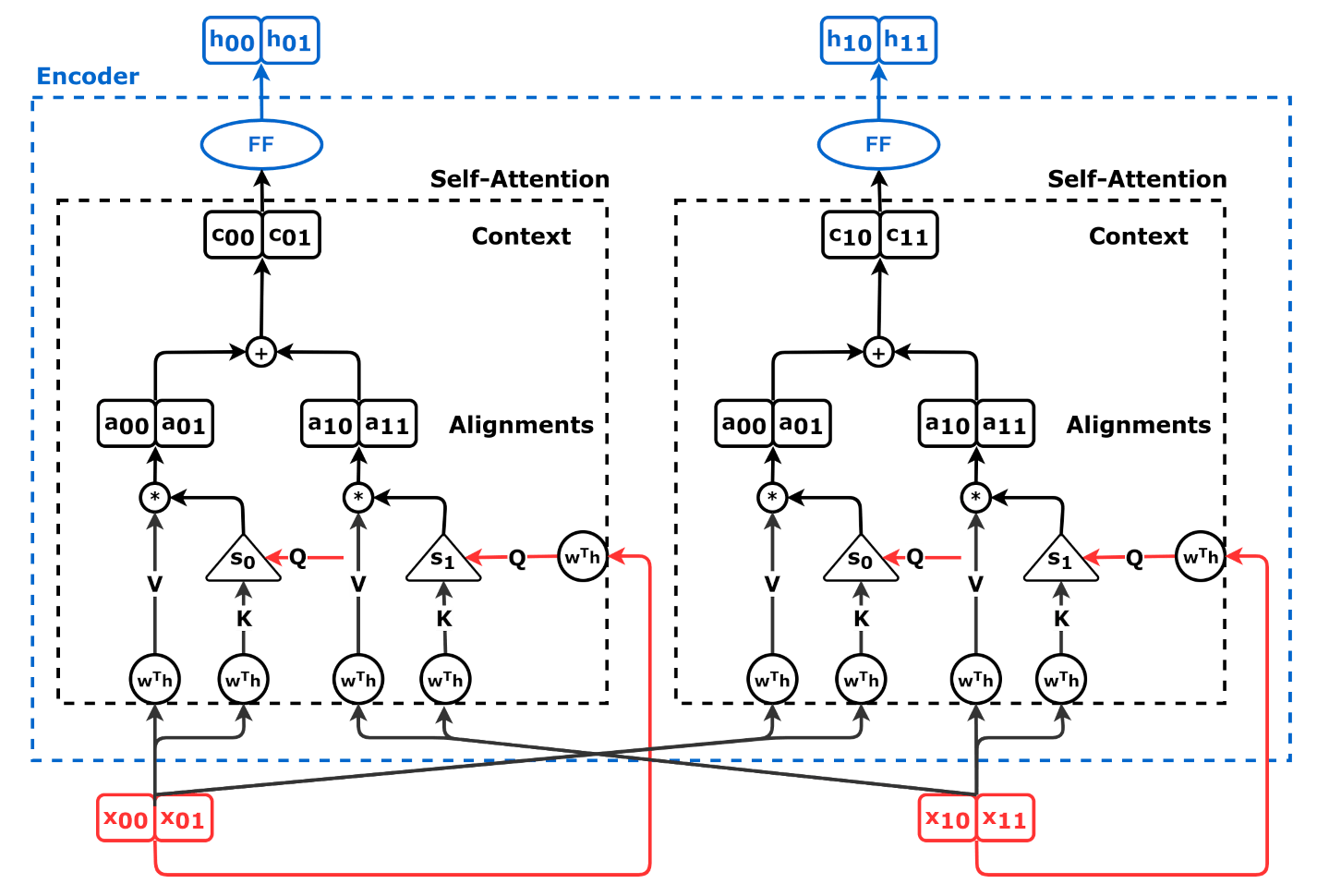 Source: Chapter 9
Source: Chapter 9
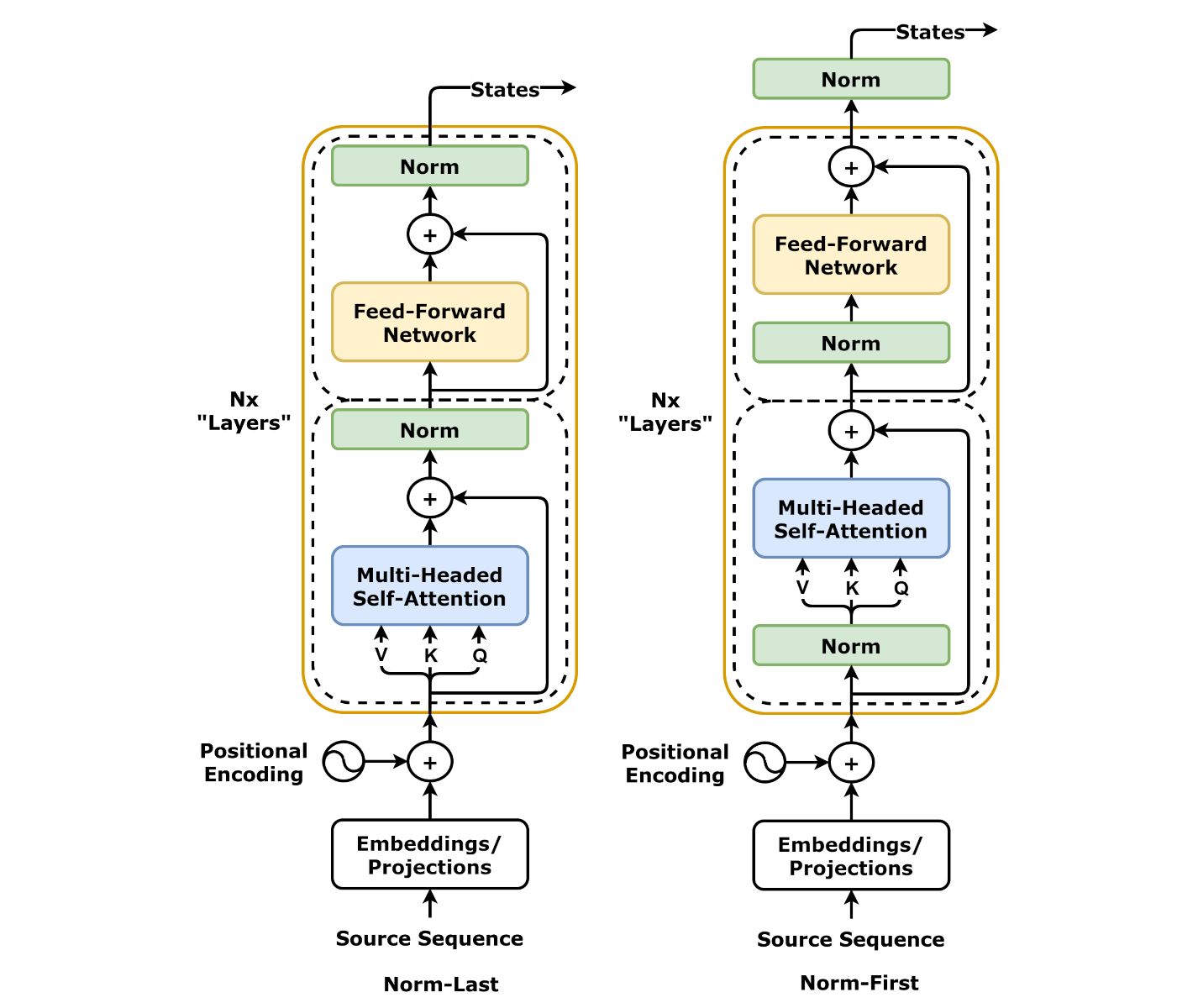 Source: Chapter 10
Source: Chapter 10
Self-Attention Decoder
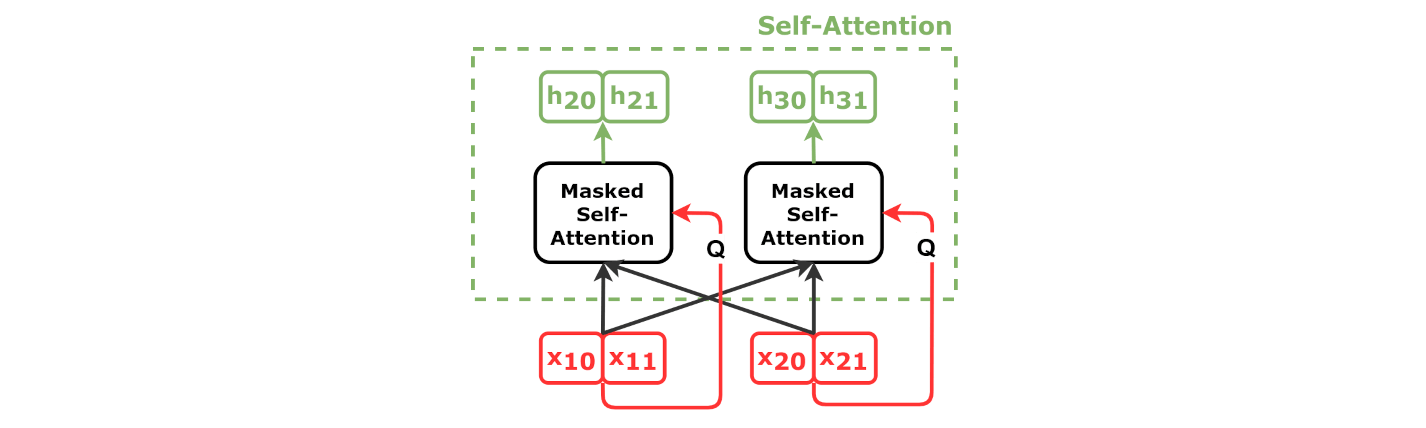 Source: Chapter 9
Source: Chapter 9
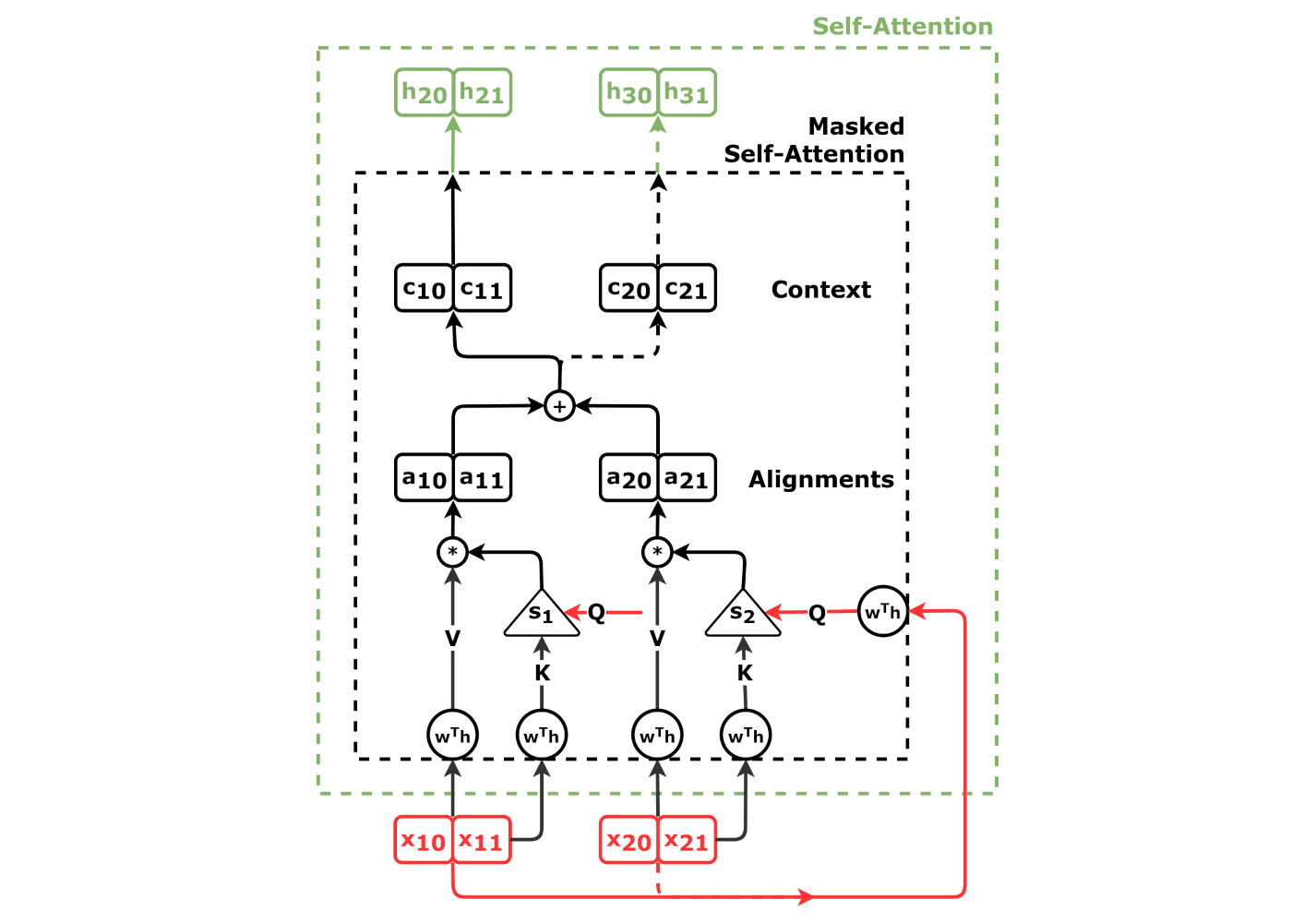 Source: Chapter 9
Source: Chapter 9
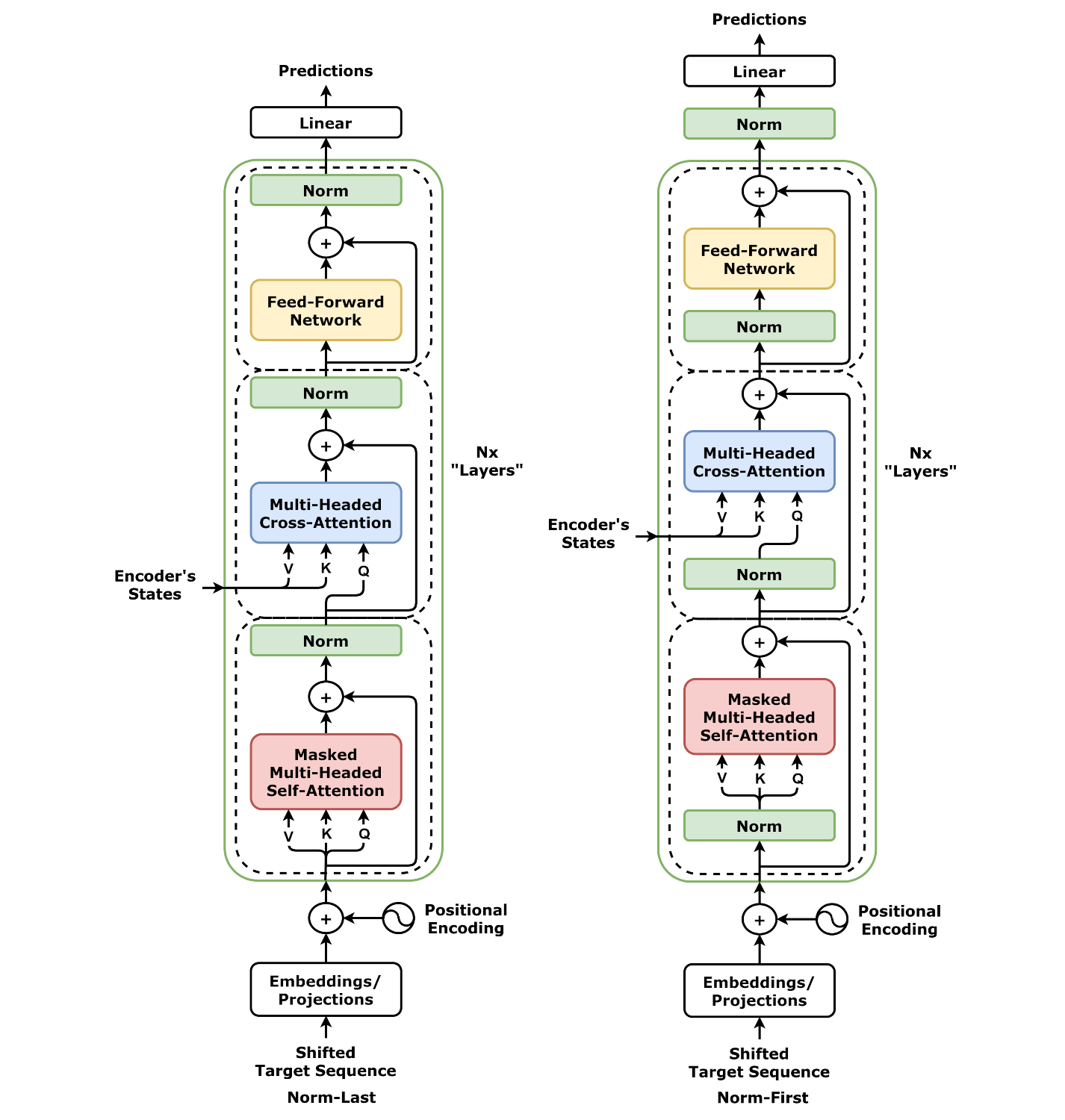 Source: Chapter 10
Source: Chapter 10
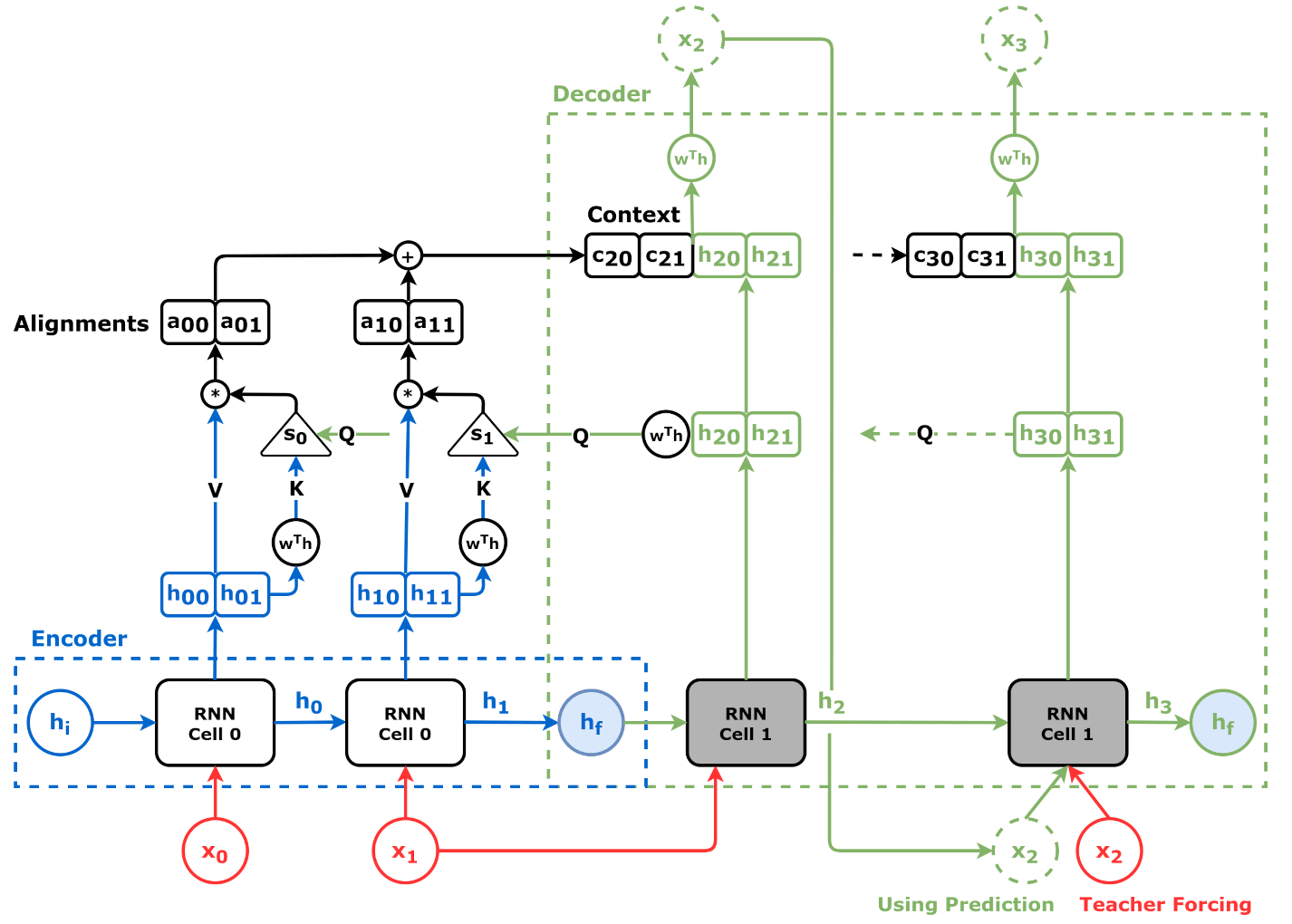
Encoder+Decoder
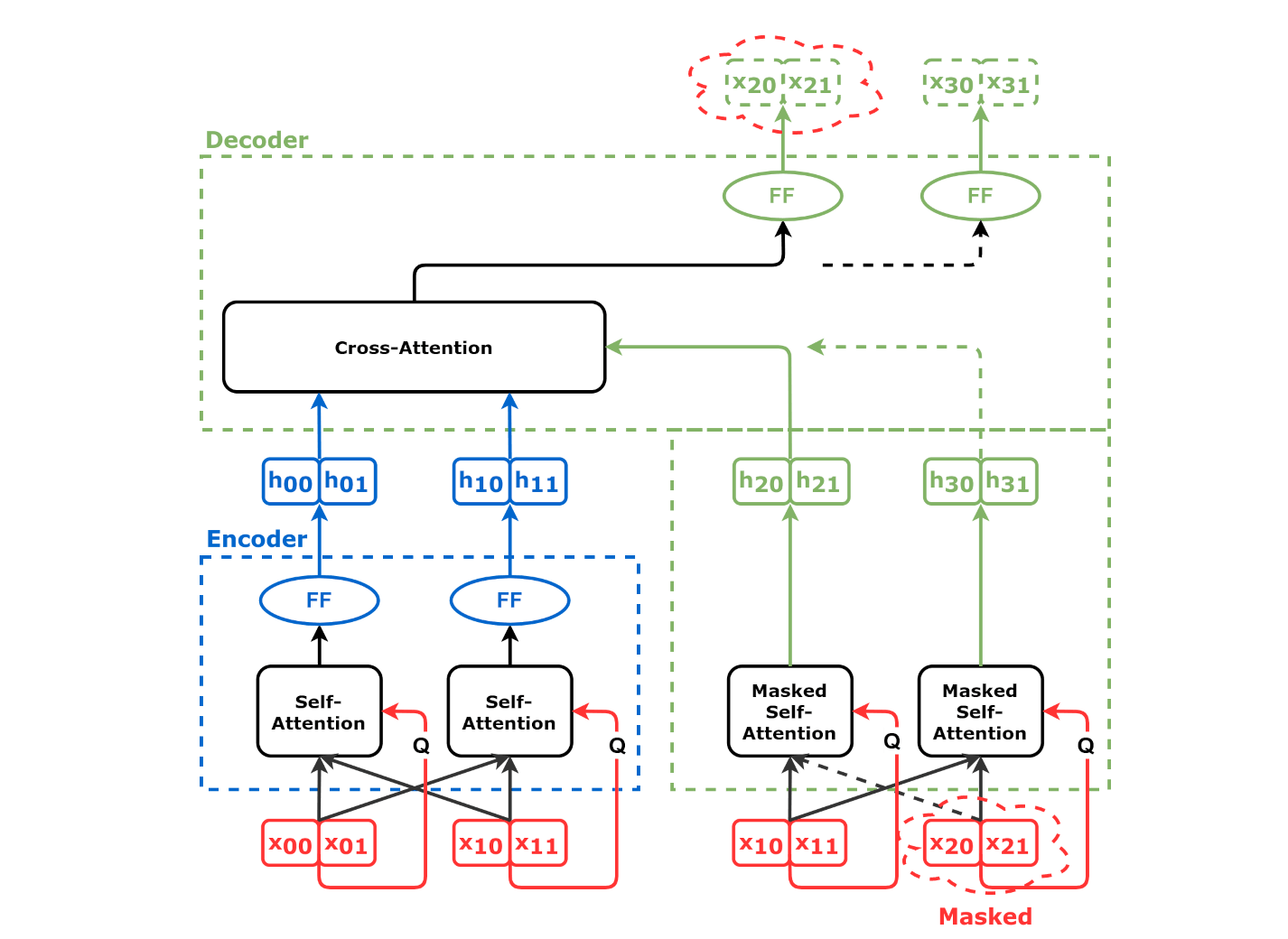 Source: Chapter 9
Source: Chapter 9
This work is licensed under a Creative Commons Attribution 4.0 International License.
